
Web crawling involves gathering data from websites. This practice is widespread on the internet today. However, the ethics of web crawling are often ignored. It’s crucial to consider the potential effects on websites and users. Let’s explore what web crawling is, how it functions, and the ethical implications involved. We will delve into the facts surrounding web crawling and ethics.
Web Crawling Defined
Web crawling is automated browsing of the web to access data from websites. It helps in collecting information from the internet, such as data on social networks and websites like LinkedIn or Facebook.
This process is also referred to as web scraping and can be done by human users or web crawlers. Web crawlers are automated programs that follow the Robots Exclusion Protocol to access data.
Web crawling raises ethical concerns related to privacy and responsible data handling. Website owners use robots.txt files to limit access to certain parts of their site, like personal data behind login screens.
In the United States and other countries, data protection laws mandate researchers to obtain user consent and follow ethical guidelines when collecting personal information. Failing to comply can lead to legal consequences. Adhering to ethical standards and seeking legal advice when using web crawlers for business or research is important.
Purpose of Web Scraping
Web scraping extracts data from websites for research, business, or accessing public data.
Ethical web scraping provides valuable information for users and helps businesses make data-driven decisions.
For example, researchers gather user consent data for studies, while businesses analyze market trends and competitors’ strategies.
Unethical scraping, like collecting personal data without consent, can lead to legal action, data protection breaches, and reputation damage.
Responsible practices involve getting user consent, respecting robots.txt files, and handling personal data ethically.
Web scrapers must know data protection laws, intellectual property rules, and privacy regulations, especially in countries like the US and China with strict data protection laws.
Web Crawling Laws & Ethics
Legal Considerations
Web crawling and scraping without proper permission can lead to legal issues. This includes violating data protection laws, accessing personal information without consent, and potentially infringing on intellectual property rights.
To avoid these problems, companies should follow these practices:
- Respect website terms of service.
- Obtain consent for web crawling activities.
- Implement responsible data handling practices.
- Adhere to robots.txt files.
- Obtain user consent for accessing personal data, especially on login screens or social network data.
It’s important to be aware of laws and regulations in different countries, such as the United States and China, as they may have different rules regarding web scraping, privacy, and data extraction.
Following ethical guidelines, seeking legal advice when necessary, and practicing responsible scraping methods are essential to prevent legal consequences and ethical issues related to web crawling activities for research and business purposes.
Ethical Implications
When engaging in web crawling or scraping, it’s important to consider ethics. Here are some key points to keep in mind:
- Transparency, consent, and respect for website terms of service are vital when extracting data.
- Website owners have the right to set rules for accessing their content.
- Violating these rules can have legal consequences. For example, scraping personal data without consent on login screens can break data protection laws.
- Researchers must follow ethical guidelines like respecting robots.txt files and handling data responsibly.
- Failing to do so can lead to issues such as intellectual property infringement and privacy breaches.
- Understanding ethical standards and laws is crucial, especially in countries like the United States and China with strict rules on personal information.
- Responsible scraping not only safeguards privacy but also maintains the web’s integrity and protects businesses and users from harm.
The Role of Robots.txt
Robots.txt helps control web crawling activities on websites.
Implementing the robots exclusion protocol allows website owners to decide which parts of their web pages can be crawled by automated web crawlers.
Website owners can also specify which parts should not be accessed.
This helps protect user privacy, intellectual property, and prevents excessive requests that could overload server capacity.
Tech companies like Reddit use robots.txt to prevent personal data scraping and unauthorized user data access.
Reddit for example has a very extensive list of rules in their robots.txt which should prevent a lot unauthorised bots to crawl their site:
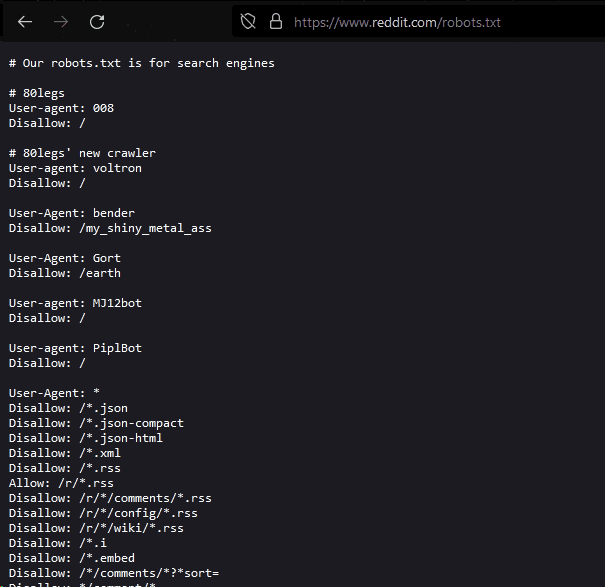
Ignoring robots.txt rules can result in legal consequences, like breaching data protection laws in the US and China.
Researchers performing web scraping for approved studies must follow ethical guidelines and get user consent.
Being responsible with data and respecting robots.txt rules are crucial in upholding ethical standards and avoiding legal issues when using publicly available data for business purposes.
Web Scraping Regulations
Country Dependent
Web crawling and web scraping involve legal and ethical considerations in different countries.
In the United States, laws like the Computer Fraud and Abuse Act and the Digital Millennium Copyright Act regulate web crawling to safeguard personal data and intellectual property.
China has stricter rules on accessing online social networks data, focusing on user consent and responsible data use.
For research purposes, researchers using web crawling must follow the country’s standards and may need to obtain user consent in many countries.
Web scraping can affect authors’ rights by potentially misusing their data for business reasons.
To protect personal information and website owners’ rights, web crawlers should respect websites’ terms of service, adhere to the Robots Exclusion Protocol, and avoid excessive requests.
Responsible data handling and ethical standards are crucial to prevent legal issues and ensure personal data protection on the web.
Impact on Authors
Web scraping and web crawling can impact authors when their work is involved. Authors should consider ethical concerns when their content is scraped or crawled. Protecting work from misrepresentation or unethical use is important for authors. Knowing legal advice and data protection laws can safeguard personal data and intellectual property. Following ethical guidelines and handling data responsibly are key to avoiding consequences of unethical scraping.
Authors can protect their work by using robots.txt files and login screens to prevent excessive requests or unauthorized access. User consent and responsible scraping practices are crucial for maintaining ethical standards in data extraction. Balancing data access for research purposes and respecting privacy is essential for authors in the United States and worldwide.
Ensuring Ethical Web Crawling
Transparency and Consent
Organizations can promote transparency and seek user consent during web scraping. They should clearly explain data collection practices and goals. For instance, when gathering Facebook data for research, researchers need to inform users and obtain consent prior to accessing personal information. It’s important to follow ethical guidelines and data protection laws, especially in the United States, to avoid legal issues.
Responsible data handling includes obtaining permission to scrape websites and complying with robots.txt files to safeguard user privacy. To uphold website terms of service, organizations should engage in interactive web crawling rather than heavy use of automated bots. Ethical standards are necessary to prevent unauthorized scraping of personal data from social networks. By adhering to protocols like the IRB for human subjects research and seeking legal guidance, businesses can responsibly conduct web scraping activities.
Respecting Website Terms of Service
When engaging in web crawling, it’s important to follow a website’s Terms of Service. This helps avoid potential consequences, including legal issues and ethical concerns. Transparency and getting user consent are key for ethical web crawling.
For example, when gathering data from Facebook or TechCrunch, it’s vital to comply with ethical guidelines and data protection laws. Checking for robots.txt files and limiting requests can safeguard website owners’ rights and users’ privacy.
Researchers should handle personal data responsibly and only use publicly available data for research. Adhering to standards like the robots exclusion protocol ensures ethical web crawling practices for humans and machines.
When dealing with personal data scraping or user login screens, obtaining user consent is crucial. This is especially important in countries like the United States with strict data protection laws. Following ethical guidelines and Terms of Service is not just a legal requirement but also crucial for privacy protection and fostering trust online.
Consequences of Unethical Web Scraping
Legal Ramifications
Individuals and businesses who engage in web scraping should think about the legal implications. Accessing and extracting data from websites requires careful consideration. Unethical web crawling practices, like ignoring robots.txt files or bypassing login screens for personal info, can lead to legal trouble under data protection laws. To stay compliant, it’s important to get user consent, handle personal data responsibly, and follow ethical guidelines.
Failing to do so can lead to serious consequences, including fines and legal actions. Researchers gathering data for studies should meet ethical standards, like getting IRB approval for data involving humans. Respecting websites’ terms of service and the Robots Exclusion Protocol is crucial to avoid legal problems. In the U.S. and other countries, web crawlers accessing social network data must be aware of scraping publicly available data without consent or using it for business without authorization.
Conclusion
Web crawling uses automated bots to scan websites for data. Ethical concerns come up when web crawling breaks website rules or violates privacy. To crawl ethically:
- Follow robots.txt rules.
- Respect website owners’ requests.
- Prioritize user privacy.
Know ethical issues well to prevent legal problems.