
One of the most difficult aspects of any web scraping operation, large or small, is managing the many proxies required. The various proxy management challenges include dealing with a huge number of requests, implementing effective proxy management logic, ensuring that all the data gathered is accurate, and ensuring that your proxy management program does not crash or get blocked by websites. Read on to learn more about the proxy management challenges that content aggregators have to overcome when they are running their web scraping operations.
The Astronomical Number Of Requests
Perhaps the single most difficult challenge that content aggregators have to face when managing their web scraping proxies is dealing with the massive number of requests such an operation requires. Of course, this many requests require many IPs. Not only will you need quite a few IPs, but you will also need a variety of IP types. You will need both datacenter/residential IPs and location IPs. Location IPs are necessary because many sites will display different data depending on the geographic location of the IP accessing the site. For example, a news site may display different stories based on the IP’s location.
Implementing Effective Proxy Management Logic
Another huge challenge for content aggregators when it comes to managing their web scraping proxies is implementing effective proxy management logic. Many websites have captchas, for example, which will clog up your web scraping operation in a hurry. Good proxy management logic will help your operation get around captchas and similar problems. This can be difficult to engineer yourself unless your people have a great deal of experience creating similar programs. It may be easier to go with an off-the-shelf program, for this and other reasons.
Getting Accurate Data
Web scraping will certainly return quite a lot of data in a hurry. However, this data isn’t worth much unless it is accurate. Believe it or not, some websites will intentionally put out inaccurate or misleading data if they detect a web scraping operation. Some websites want to discourage web scraping because they cannot make money off of web scraping users. Well-constructed proxy management logic will detect this practice and ensure that you get accurate data.
Building A Reliable Web Scraping Program
Web scraping programs are large and complex. Like all complex programs, web scraping programs can crash or suffer from glitches. However, this downtime is essentially wasted money for your company. It is imperative that your web scraping program is as reliable as possible. Otherwise, your company’s content aggregation will be very inefficient.
Creating Your Own Proxy Management Solution Vs. Obtaining An Off-The-Shelf Solution
All things considered, obtaining an off-the-shelf proxy management solution is the right choice for many businesses. This is certainly the most popular choice, as companies that create their own custom programs are usually large corporations with many software engineers on staff. Unless you have software engineers on staff who can reliably create a proxy management program, it’s probably best to get a program off of the shelf.
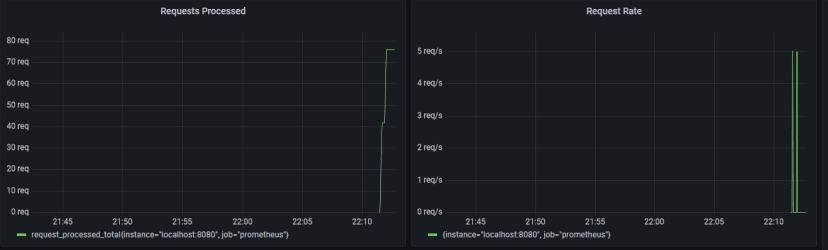
How is SpeedProxies solving this issue?
Such a system will require a lot of hard work to get to work with off the self solution as there are many but they aren’t user friendly or they are too simple and don’t have much features, this is where SpeedProxies comes in, we are developing our own custom written proxy load balancer writting in Golang for our backend servers and we will introduce a dashboard customers can drop in their proxies, we will give them a IP:PORT or IP:PORT:USER:PASS endpoint that will let them send requests to and we handle the load balancing across the proxies, our current ETA for this is Q4 2022.